به پارک علم و فناوری دانشگاه صنعتی شریف خوش آمدید
پارک علم و فناوری دانشگاه صنعتی شریف در سال ۱۳۹۵ تأسیس شد. با شکلگیری پارک، فعالیتهای مرتبط با کارآفرینی و شکلگیری شرکتهای دانشبنیان در دانشگاه صنعتی شریف که به تدریج از سال 1379 توسعه یافته بودند، به صورت یکپارچه زیر نظر پارک قرار گرفت.
این مجموعه به عنوان یک پارک دانشگاهی در نظر دارد تا با ایجاد یک تعامل برد-برد میان بدنۀ علمی دانشگاه و دیگر نهادها به یک الگوی ملی در زمینه توسعه پایدار و ارزشآفرینی در سطح جامعه تبدیل شود.
هویت بخشی به ناحیه نوآوری شریف در اطراف پردیس اصلی دانشگاه و کمک به رونق کسبوکارهای فناوران مستقر در این ناحیه یکی از برنامه های مهم پارک محسوب میشود.
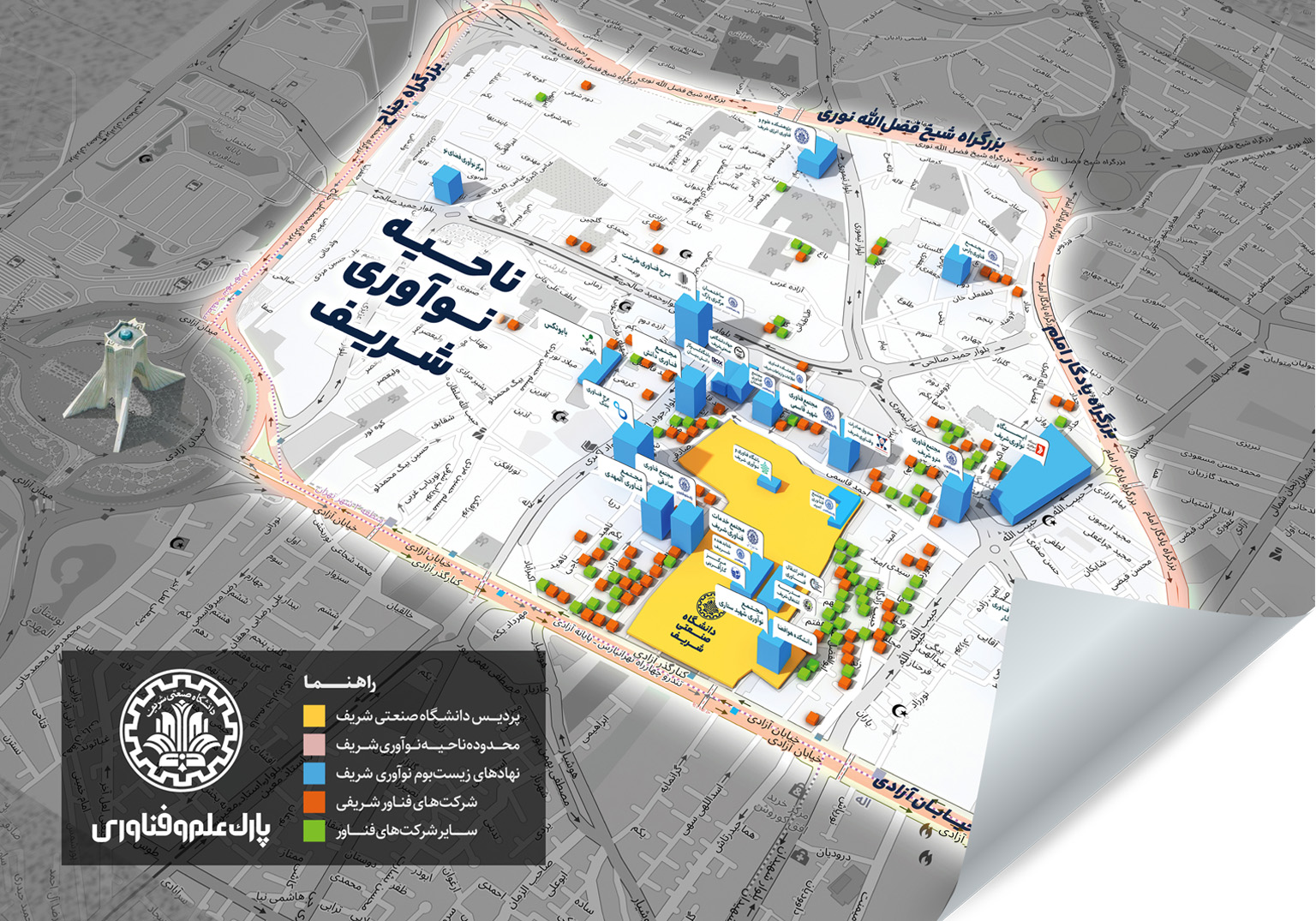
ناحیه نوآوری شریف
ناحیه نوآوری شریف با شعار «کانون امید و ارزشآفرینی» در دیماه ۱۳۹۷ به طور رسمی به جامعه فناوران و نوآوران معرفی شد. این فضای نوآور با وسعت ۲۵۰ هکتار شامل 600 کسبوکار فناور و نوآور در صنایع مختلف است که برای «خلق ارزش مشترک» متناسب با مأموریت، توانمندی و شایستگی محوری خود به ایفای نقش میپردازد. مهمترین اصل در ناحیه نوآوری شریف، توسعه با محوریت بخش خصوصی و بدون مشارکت مستقیم نهادهای دولتی است. پارک علم و فناوری دانشگاه صنعتی شریف به عنوان متولی راهبری این ناحیه، تسهیلگری لازم را در ورود کسبوکارهای فناور و رشد بازیگران زیستبوم نوآوری و کارآفرینی در منطقه انجام خواهد داد تا ارزشآفرینی حداکثری محقق شود. ناحیه نوآوری شریف به زودی تبدیل به قطب توسعه کسبوکارهای فناور و دانشبنیان در پایتخت ایران خواهد شد.